Table of Contents
Introduction
LynxKite from Lynx Analytics is a graph analytics platform. It is built on top of Apache Spark, so it can scale up to any size of data. It is a Big Data tool, so it is compatible with popular Big Data platforms such as Hadoop, Amazon EC2 or Amazon EMR.
LynxKite Architecture Summary
At a glance
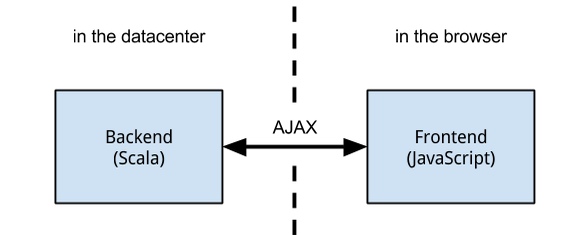
Like a typical web application, the backend runs in a datacenter (in a single Java VM) and serves a rich frontend running in the user’s browser. The server only serves static files (HTML, JavaScript, CSS and images) and dynamic JSON responses. Avoiding dynamically generated HTML eliminates a large class of security issues.
The following sections go into more detail about the architecture of both the backend and the frontend.
The Backend
The two technologies underpinning the LynxKite backend are Apache Spark, a distributed computation framework, and Play! Framework, a web application framework.
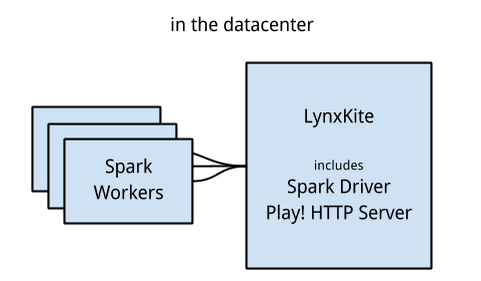
Apache Spark can scale to thousands of machines. The distributed computation is coordinated by the Spark Driver application, which is the LynxKite server in our case. This server is the only proprietary component in the system. Besides acting as the Spark Driver, it also acts as the Play! HTTP Server, serving static files and dynamic JSON content to the frontend.
LynxKite installation modes
There are two ways for scheduling/hosting the Spark executors.
-
In
localmode, there is only one worker which runs as part of the main LynxKite process, this is ideal for single machine installations. -
In
yarnmode we use the built-in support of Apache Spark for running as a Hadoop YARN application. In this case the Spark driver runs outside of YARN, starts a simple application master on YARN and asks it to start the executors.
Storage
Apache Spark includes the Hadoop client libraries. This gives LynxKite the capability to access
file systems supported by Hadoop, such as HDFS, S3, and GCS. Data files can be imported from
and exported to these file systems. JDBC is used to import from and export to SQL databases.
JDBC drivers for some popular database vendors are included. To add more JDBC drivers, copy
them into the directory specified by EXTRA_JARS. (As explained in The .kiterc file.)
LynxKite needs some storage space on a filesystem to store internal graph data. This filesystem has to be accessible by all workers. Because of this requirement, in most cases this needs to be a distributed file system with fast access from the Spark workers. Ideal setups include using S3 when running on Amazon EMR or using the HDFS of the same cluster when running using Hadoop YARN. On single machine installations one case simply use local hard disk for this purpose.
Notably the LynxKite process runs on a single machine. This is a design decision on the part of Apache Spark. While it introduces a single point of failure, it does not create a scaling bottleneck, since all the computation work is performed by the Spark Workers.
The Frontend
The LynxKite frontend is an AngularJS application.

AngularJS provides routing, REST request handling, and custom HTML element management that is used to define the LynxKite frontend modules. The defining feature of AngularJS is two-way data binding, which is the glue that ties the LynxKite frontend modules together.
The project management view is regular dynamic HTML.
The 2D visualization is a single large embedded SVG element that is dynamically constructed by the responsible LynxKite frontend module.
The 3D visualization is managed by another module and is a WebGL canvas used via the Three.js general-purpose JavaScript 3D library.
Minor utility libraries are also used, such as Chroma for color manipulation.
Sizing the cluster
This section is about planning the size and hardware configuration of the cluster hosting LynxKite.
LynxKite RAM requirements
LynxKite is able to complete operations even with a very small amount of memory compared to the size of the data. So there are no hard data size dependent RAM requirements. Of course, operations will be much faster if the data can be kept in memory continuously. To have an idea of how much memory is needed for that depending on your graph data, see the sections below.
The RAM Formula
How much RAM does LynxKite need in the cluster to be able to work with a data set in memory? The following formula is easy to remember and gives a rough estimation.
To import a CSV of L lines and N columns as vertices, LynxKite needs Bv bytes.
Bv = L × 200 × (N + 1)
Each column needs 200 bytes, and one more column, the vertex ID, is generated.
To import the same CSV of L lines and N columns as edges, LynxKite needs Be bytes.
Be = L × 200 × (N + 3)
The edges also get an ID, plus they store the source and destination vertex ID.
These formulas assume columns of around 10 characters. If a column contains significantly more characters, add 2 bytes per character. For a less accurate estimate, we can say that LynxKite needs X × 20 — X × 30 bytes of RAM for working with data that is X bytes on disk.
A Simple Example
Let us say we have a CSV with two columns, src and dst: N = 2. It contains 100 million lines: L = 100,000,000. To import this graph, we need Be = 100,000,000,000 which is 100 GB of RAM.
Number of Machines
Getting from the amount of RAM to the number of machines is mostly trivial. There is some overhead, but the formula is loose enough to accommodate that. So if we have 32 GB machines and need 100 GB of RAM, we can just say we need 100 / 32 = 3.125 rounded up to 4 machines. This is the number of worker machines. One extra machine is needed which serves as the master and the web server.
If you need B bytes of RAM and have C bytes of RAM per machine, you need M machines (rounded up).
M ≥ B / C + 1
See the The 32 GB rule for more tips.
Disk space
LynxKite uses a lot of storage for processing and hosting data.
Storage capacity for data hosted by LynxKite
As a rule of thumb it is recommended to plan at least with 10 times of the storage capacity of the original data. So if you have 100 GB data to analyse in LynxKite have at least 500 GB set aside for permanent storage.
Storage capacity for temporary data
During computation Spark creates temporary files. These files are cleaned up by Spark (once they are not needed) or after restarting LynxKite. The size of these files depend on a lot of things but it is generally recommended to set aside at least 200 GB for them on each Spark executor.
See Configure directories for more details.
Logging
LynxKite logs various activities. The log directory can be configured in the .kiterc file.
The application log
The main log of LynxKite is the application log. LynxKite creates a new log file every day (except for those days when it is not used). It automatically deletes the log files older than 60 days.
The application logs the following activities (among other things):
-
User login attempts, successful logins and logouts.
-
All HTTP requests received by the web server including the user and the URL.
-
Accesses of files in the
KITE_DATA_DIR.
Admin users can browse and download these logs using the <LynxKite_URL>/#/logs URL.
STDERR and STDOUT
Every time LynxKite is started a log is created for STDERR and STDOUT with the process ID of the application. These logs generally do not contain much information unless something went wrong during the startup process.
Installation
Recommendations
Hardware
It is recommended to have at least 16 GB RAM per machine. It is optimal to have around 4 GB RAM per CPU core. It is common to use 32 GB RAM machines with 8 CPU cores. LynxKite needs a lot of storage for computed data, so we recommend to have a sufficiently large distributed file system (e.g., HDFS). The needed capacity depends heavily on the way LynxKite is used, but it is recommended to plan with at least 5x of the initial data size. For temporary computation files it is recommended to use a smaller but faster drive (e.g. a partition on an SSD with at least 100 GB).
Software
LynxKite runs on any modern Linux distributions. We recommend using Ubuntu Server 14.04 LTS or CentOS/Redhat 6.7, because LynxKite has been tested on those systems.
Requirements
Java version
You need Java 8 on the system.
Write permission
You need write permission to the directory configured as KITE_DATA_DIR. On HDFS a home directory
is also required for the user that starts LynxKite. Example commands to create these directories:
-
sudo -u hdfs hadoop fs -mkdir hdfs://$NAMENODE:8020/kite_data -
sudo -u hdfs hadoop fs -mkdir hdfs://$NAMENODE:8020/user/$USER -
sudo -u hdfs hadoop fs -chown $USER hdfs://$NAMENODE:8020/kite_data -
sudo -u hdfs hadoop fs -chown $USER hdfs://$NAMENODE:8020/user/$USER
Port collision
By default LynxKite runs on port 2200. If this is used by another process, move LynxKite to a
different port (by changing the KITE_HTTP_PORT setting in .kiterc).
YARN settings
YARN memory limit
Set the executor memory (EXECUTOR_MEMORY) lower than the YARN NodeManager memory limit defined
with the yarn.nodemanager.resource.memory-mb and yarn.scheduler.maximum-allocation-mb settings
in the YARN configurations.
Smart YARN memory monitor
If allowed by the YARN administrator, set
yarn.nodemanager.container-monitor.procfs-tree.smaps-based-rss.enabled to true in the
YARN configuration. This will prevent the YARN nodemanager from incorrectly including
shared memory regions in the total physical memory used by Spark executors. Not setting this
flag may result in the node manager unjustly but mercilessly shutting down the executor.
The 32 GB rule
The Java Virtual Machine can be configured to use practically any amount of RAM on a 64 bit system.
However its efficiency breaks down after 32 GB. Therefore a JVM with 40GB RAM is actually worse
than a JVM with 32 GB RAM. For that reason it is not recommended to set the EXECUTOR_MEMORY above
32 GB. It makes more sense to create multiple executors with less amount of RAM per executor.
Configuring LynxKite
The .kiterc file
You need to create a site configuration to be able to run LynxKite. If you don’t have a config file
created yet, running the runner script will warn you and point you to a template config file. Just
copy that template to your home directory with name .kiterc and edit the settings as necessary.
The settings are documented inside the template file and in the The .kiterc file section. This
information is also available in the template file as comments.
Using environment variables
Configuration options can also be set using environment variables. This also works when running via the standard docker image.
If an option is set both in an environment var and in .kiterc then the environment variable’s value takes precedence.
Configure directories
This is a best practices section on how to configure various directories properly. The default configuration provided by Hadoop may be suboptimal.
-
DataNode directories should be on a large drive. Set
dfs.data.diranddfs.datanode.data.diron every DataNode accordingly. -
NameNode and DataNode directories are better to not exist or at least be empty before you start the HDFS service the first time / deploy a new node. Check
dfs.name.dir,dfs.namenode.name.dir,dfs.data.diranddfs.datanode.data.dir. -
Datanode directories have to be owned by
hdfs:hadoop. -
YARN log dirs should be on a large drive. Check
yarn.nodemanager.log-dirsandhadoop.log.dirin the NodeManager andhadoop.log.dirin the ResourceManager configuration. -
YARN log dir has to be owned by
yarn:hadoop -
Set the
yarn.nodemanager.local-dirs(YARN app cache and file cache) to be on the appropriate drive. It should be sufficiently large (typically at least 100GB). -
Make sure that you have properly configured prefixes if you need them as described in the Prefix definitions section.
Running LynxKite
LynxKite can be started with the lynxkite command in the bin directory of the LynxKite installation.
For example: kite_2.6.2/bin/lynxkite start. Use the
start / stop / restart options if you want to run it as a daemon. Or, you can use the
interactive command option, which starts up the program tied to your current shell session, so its output
will appear in the shell and pressing Ctrl-C or closing the shell session will terminate the
program.
HTTPS setup
To enable HTTPS, a certificate is required. For testing purposes a self-signed certificate is
included (conf/localhost.self-signed.cert). Its password is “keystore-password”. This certificate does
not provide proper protection. (Lacking a trusted CA, the self-signed certificate can easily
be spoofed.) Using it will trigger a certificate warning in the user’s browser. It is recommended
to install a real certificate in its place.
Please refer to the HTTPS setup in the .kiterc file for more details.
Backups
Once LynxKite is up and running, take a moment to think about backups. The solution is entirely dependent on the site and purpose of the installation. But consider that LynxKite deals with the following data:
-
Import/export.
-
Graph data in
KITE_DATA_DIR. The vertices, edges and attributes of the graph. This data is stored on a distributed file system. This typically provides resilience against data loss. -
Project metadata in
KITE_META_DIR. The operations that have been executed on the project and their parameters. This data is small, and contains everything required to regenerate the graph data, assuming that the imported files are still available. This data is critical, and backups are recommended.
There is a backup tool for Hadoop deployments shipped with LynxKite under
tools/kite_meta_hdfs_backup.sh. It is recommended to create a cron job running this tool on
a daily basis (or more frequently if needed). The tool creates a copy of the full KITE_META_DIR
and the .kiterc file in HDFS.
To restore an earlier version of LynxKite simply copy the .kiterc file and the meta
directory back from HDFS to overwrite the current versions of them, then restart LynxKite.
Extra libraries
You can provide extra jar files that will be added to the CLASSPATH of LynxKite server if needed,
as specified here.
Integration with Hive
Overview
Hive stores the actual data on HDFS (usually under the /user/hive/warehouse directory), while the
metadata (location of the underlying file, schema, …) of the tables is stored by Hive Metastore.
When Spark wants to import a Hive table then it first asks the Hive Metastore for the metadata then
tries to import directly from the underlying files.
This means that for Spark to import a Hive table, it needs:
-
to know how to access the Hive Metastore;
-
to have the authorization to access the Hive Metastore;
-
to have the authorization to read the metadata of the table;
-
to have read access for the underlying file on HDFS.
Telling Spark how to access the Hive Metastore
The simplest way to do this is to create a symbolic link from the conf directory under the Spark
installation directory LynxKite is using to the hive-site.xml file.
E.g. depending on your Hadoop distribution, something like this would do:
ln -s /etc/hive/conf/hive-site.xml ~/spark/spark-<version>/conf/Getting authorization to read the metadata of a table
Hive Metastore server supports Kerberos authentication for Thrift clients, so it is possible that on clusters using Kerberos the access to Hive Metastore is restricted to only a subset of Kerberos users.
To see if that is the case on your cluster, check the hadoop.proxyuser.hive.groups property in
the core-site.xml on the Hive Metastore host. If its value is set to * or it is not set then
that means that there is no restriction on who can access the Hive Metastore. However, if it
contains a list of groups, then add the group of the user running LynxKite to the list.
For Cloudera-specific details, see the Cloudera 5.6 documentation on Hive Metastore Security.
If the impersonating concept is not clear from the above article, then the general idea is better explained here.
Getting authorization to read the metadata of given table
Hive offers 3 authorization options.
-
Storage Based Authorization in the Metastore Server: this means that the user has the same access right for the metadata as he has for the underlying data on HDFS.
-
SQL Standards Based Authorization: Like in a MySQL database you add privileges to users.
-
Default Hive Authorization (Legacy Mode): Uses roles to group grants. These roles then can be assigned to users, groups or to other roles.
Getting authorization to read the underlying file on HDFS
Please consult with the owner of the cluster to give you read access for all the corresponding files.
Known issues
With some Hive configurations, LynxKite cannot import tables due to a missing jar file. We cannot
distribute that jar file (com.hadoop.gplcompression.hadoop-lzo-0.4.17.jar) due to licensing reasons.
You should download it yourself and put it in the directory specified by KITE_EXTRA_JARS (see The .kiterc file).
Sometimes the values in an imported table all become nulls. This is a case-sensitivity issue.
Hive is case insensitive when it comes to table names and column names. Because of this, Hive
Metastore stores the column names in all lower case. But Parquet files and ORC are case preserving.
This can result in a situation where a column name is stored in all lower-case in Hive Metastore
but the same column name in the underlying files is stored using upper-case letters. Spark imports
data directly from the underlying files but uses the column names stored in Hive Metastore to look
for the columns it needs to import.
Thus if the underlying files have a column name containing upper-case letters then Spark tries to
import data from a non-existing column (since the column name is written differently in the
underlying files than in Hive Metastore) and this results in columns with all nulls.
One exception is the partitioner column - since the partitioner is part of the HDFS path, Hive
Metastore is forced to store it in a case preserving manner.
So if you can change the schema of the underlying files without causing problem then that is the
fix. If not, then create new tables whose underlying files' column names are all in lower
case. For example, the following query can be used:
CREATE TABLE <new_table> AS SELECT * FROM <old table>.
Integrating with High Availability mode HDFS
LynxKite is compatible with HDFS running in High Availability mode. In this case the HDFS prefixes
i.e. the KITE_DATA_DIR variable in The .kiterc file and the Prefix definitions need to use the
appropriate name service defined in the hdfs-site.xml configuration file of Hadoop (e.g.
hdfs://nameservice1/user/my_user/my_dir). Make sure that the file is available in the
YARN_CONF_DIR. Please refer to the related
Hadoop documentation
for more details.
LynxKite with Kerberos
LynxKite supports running on Kerberos-secured clusters. To enable this, you will need to set
KERBEROS_PRINCIPAL and KERBEROS_KEYTAB in your .kiterc respectively.
The Kerberos configuration (krb5.conf) must also be accessible on the machine where LynxKite
is running. If LynxKite is running inside a Docker container, make sure this file is passed in,
for example through a mount. The path to krb5.conf can be configured with the KRB5_CONFIG
environment variable.
You will need to contact your administrator to obtain the keytab file. In a typical setup, you
could do the following to obtain a Keytab file. Start the ktutil shell and then enter:
addent -password -p principal_user@PRINCIPAL_DOMAIN -k 1 -e RC4-HMAC
wkt lynx.keytab
exitIf you need to access the cluster from command line tools, such as hadoop, hdfs or yarn,
then you may need to run the kinit program to obtain a ticket-granting ticket for
these.
Troubleshooting
YARN memory limit
When trying to start LynxKite on YARN, you may hit the YARN per-application memory limit. LynxKite will log an error message, such as:
Required executor memory (12288+384 MB) is above the max threshold (7003 MB) of this cluster!See YARN memory limit for the fix.
Disk runs out of space
This can be due to many reasons such as various logs, Spark shuffle files, the LynxKite data files etc. See Configure directories for more details and fixes.
LynxKite UI becomes very slow and unresponsive.
This can be happen due to a huge set of possible reasons. Logged in administrator users can get a thread dump
that reflects LynxKite’s internal state via the url `<LynxKiteUrl>/getThreadDump.
(E.g., http://localhost:2200/getThreadDump). This will come in handy when debugging the issue.
LynxKite configuration files
Starting or deploying LynxKite requires certain properly set environment variables. As explained
before LynxKite ships with template files for these configurations. The following sections specify
these variables in specific setups. If the example code starts with the # sign it means the
variable is disabled by default in the shipped corresponding template file.
The .kiterc file
This file contains various configurations used when launching a LynxKite instance.
Settings in this file can be overriden using environment variables. See section Using environment variables for more details.
To specify which cluster to use choose one of the following options:
-
local- for single machine installs -
yarn- for using YARN (Hadoop v2). Please also setYARN_*settings below.
export SPARK_MASTER=localSpecify the directory where LynxKite stores metadata about projects. The directory must be on the local file system. Do not forget to set up backups.
export KITE_META_DIR=$HOME/kite/metaSpecify the directory of the data where graph data is stored. Should be on a distributed fs
(HDFS, S3, etc) unless this is a local setup. Please note that giving the full
URI (e.g., file:/…) is mandatory.
export KITE_DATA_DIR=file:$HOME/kite/data/LynxKite can use a faster ephemeral file system for data storage, with reading from the main
file system specified by KITE_DATA_DIR as a fallback. The primary use case for this is using
SSD-backed HDFS on EC2 while using S3 for the permanent storage.
If KITE_EPHEMERAL_DATA_DIR is set, all data writes go to this directory. KITE_DATA_DIR will be
used only for uploaded files.
# export KITE_EPHEMERAL_DATA_DIR=Optionally set the configuration file to specify what file paths users are allowed to access using
what prefixes. Use kite_x.y.z/conf/prefix_definitions_template.txt as a template when creating
your custom prefix configuration file. Make sure you put the config file to a LynxKite version
independent location (not inside the kite_x.y.z directory, e.g. $HOME/kite_conf). Then set
KITE_PREFIX_DEFINITIONS to point to your newly created config file (e.g. the recommended
$HOME/kite_conf/prefix_definitions.txt).
export KITE_PREFIX_DEFINITIONS=Normally, LynxKite can only access the file system via its prefix mechanism,
that is, using either the DATA$ prefix (as in DATA$/dir/file.csv) or any other
prefixes set up in a prefix definition file. This behavior can be changed by
setting KITE_ALLOW_NON_PREFIXED_PATHS to true: then it becomes possible to
specify any valid paths such as file:/home/user/kite_data/dir/data.csv
or s3n://awskey:awspassword@somedir/somefile. Be careful: all LynxKite users will
be able to read and write local and cluster files with the credentials of the LynxKite process.
Only allow this in restricted environments.
export KITE_ALLOW_NON_PREFIXED_PATHS=falseSpecify the YARN configuration directory. It is needed if you want to run against YARN.
# export YARN_CONF_DIR=/etc/hadoop/...By default, LynxKite specifies 15% of executor memory to be the amount allocated for overhead in YARN executor containers. You can set a higher value if YARN is killing your executors for exceeding size, but the executors themselves are not reporting out of memory errors.
# export YARN_EXECUTOR_MEMORY_OVERHEAD_MB=4000YARN offers the possibility of using resource pools. You can specify an existing resource pool and allocate LynxKite to it.
# export RESOURCE_POOL=Specify how much memory is available for LynxKite on a single worker machine.
Ignored for local setups, use KITE_MASTER_MEMORY_MB for that case.
export EXECUTOR_MEMORY=1gSpecify the number of executors. For standalone cluster it defaults to as many as possible. For a YARN setup, this options is mandatory.
# export NUM_EXECUTORS=5Specify the number of cores per executor LynxKite should use.
export NUM_CORES_PER_EXECUTOR=4Specify how much memory is available for LynxKite on the master machine in megabytes.
For local setups this also determines executor memory and EXECUTOR_MEMORY is
ignored in that case.
export KITE_MASTER_MEMORY_MB=1024Specify the port for the LynxKite HTTP server to listen on. Must be >=1000.
export KITE_HTTP_PORT=2200By default, LynxKite can only be accessed from localhost for security reasons. (That is,
address 127.0.0.1). Uncomment the following line if LynxKite should be accessible
from other IP addresses as well.
# export KITE_HTTP_ADDRESS=0.0.0.0Specify the HTTP port for the watchdog. If this is set, the startup script will start a watchdog as well which will automatically restart the LynxKite server if it detects any problem.
# export KITE_WATCHDOG_PORT=2202Uncomment this to start an internal watchdog thread inside LynxKite’s driver JVM. This watchdog will kill LynxKite if health checks are failing continuously for the given amount of time.
# export KITE_INTERNAL_WATCHDOG_TIMEOUT_SECONDS=1200The LynxKite local temp directory is a local path that exists on all workers and the master and will be used for storing temporary Spark/Hadoop files. This directory can potentially use a lot of space, so if you have a small root filesystem and an extra large drive mounted somewhere then you need to point this to somewhere on the large drive. On the other hand performance of this drive has a significant effect on overall speed, so using an SSD is a nice option here.
export KITE_LOCAL_TMP=/tmpConfigure the directory LynxKite uses for logging. Defaults to logs under the LynxKite
installation directory if not specified.
# export KITE_LOG_DIR=The LynxKite extra JARS is a colon (:) delimited list of JAR files that should be loaded on the
LynxKite CLASSPATH. (It will be loaded on the master and distributed to the workers.)
-
Some wildcards are supported, you can use
/dir/, but you cannot use/dir/.jar. -
Filenames have to be absolute paths.
One typical use case is to configure additional JDBC drivers. To do that, all you need to do is to add the jar file here.
export KITE_EXTRA_JARS=You can enable an interactive Scala interpreter able to access LynxKite internals by using
the below exports. You can access the interpreter by SSHing from the host running LynxKite as:
ssh ${KITE_AMMONITE_USER}@localhost -p ${KITE_AMMONITE_PORT}
and use KITE_AMMONITE_PASSWD as password.
If you do this and do not trust all users who can SSH into this machine (the typical case!)
then make sure to modify the file system permissions of .kiterc to be only readable by the
user running LynxKite and change the password below.
# export KITE_AMMONITE_PORT=2203
# export KITE_AMMONITE_USER=lynx
# export KITE_AMMONITE_PASSWD=kiteOptions needed if you want to use authentication and HTTPS.
Just use the following configurations with default values for a simple, fake certificate setup.
Application secret used by Play! framework for various tasks, such as signing cookies and
encryption. Setting this to <random> will regenerate a secret key at each restart.
More details can be found
here.
export KITE_APPLICATION_SECRET='<random>'Specify the port for the LynxKite HTTPS server to listen on. Must be >=1000.
# export KITE_HTTPS_PORT=2201Set the keystore file and password with the HTTPS keys. Use the default values for a fake HTTPS certificate. If you have your own intranet CA or a wildcard certificate, you can generate a certificate for LynxKite that the browsers can validate. Follow the instructions at Apache Tomcat for creating a keystore file.
# export KITE_HTTPS_KEYSTORE=${KITE_DEPLOYMENT_CONFIG_DIR}/localhost.self-signed.cert
# export KITE_HTTPS_KEYSTORE_PWD=keystore-passwordOn a Kerberos-secured Hadoop cluster, set the KERBEROS_PRINCIPAL and KERBEROS_KEYTAB variables. The principal acts like a user name and the keytab file acts like a password.
# export KERBEROS_PRINCIPAL=
# export KERBEROS_KEYTAB=The setting KITE_MAX_ALLOWED_FILESYSTEM_LIFESPAN_MS forces LynxKite to create a
new Hadoop Filesystem object every time KITE_MAX_ALLOWED_FILESYSTEM_LIFESPAN_MS milliseconds
have passed. This mechanism prevents certain errors related to Hadoop delegation token expiration.
A good value for this is half the time specified in the system’s
dfs.namenode.delegation.token.renew-interval setting. That defaults to 1 day, so our default is 12 hours.
See this explanation
for details.
# export KITE_MAX_ALLOWED_FILESYSTEM_LIFESPAN_MS = $((1000*60*60*12))Uncomment the below lines to export LynxKite’s Spark metrics into
a Graphite-compatible monitoring system. You can use this together
with tools/monitoring/restart_monitoring_master.sh.
# export GRAPHITE_MONITORING_HOST=$(hostname)
# export GRAPHITE_MONITORING_PORT=9109Specify any command line arguments for the jvm that runs the LynxKite driver. (e.g., EXTRA_DRIVER_OPTIONS='-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=50000' will run a local LynxKite in a such a mode that you can attach to it with a debugger.)
# export EXTRA_DRIVER_OPTIONS=Set thread stack size for thread in the executor process. By default, jvm will assign 1 megabyte for each thread, but that is too low for some rdd dependencies. The suffixes M and k can be used to specify megabytes or kilobytes respectively; e.g., 1M or 1500k. This setting does not have an effect in local mode.
# export EXECUTOR_THREAD_STACK_SIZE=3MSet thread stack size for driver threads. By default, jvm will assign 1 megabyte for each thread, but that is too low for some rdd dependencies. The suffixes M and k can be used to specify megabytes or kilobytes respectively; e.g., 1M or 1500k.
# export DRIVER_THREAD_STACK_SIZE=2MMaximize the number of parallel threads. LynxKite, Spark domain and Sphynx will all use this parameter.
# export KITE_PARALLELISM=5Specify the length of the protected time period in days, while the cleaner does not delete data files. It can be integer or double value.
# export KITE_CLEANER_MIN_AGE_DAYS=14Anonymous data collection is opt-in by default. This setting can be used to force it on or off on an instance. Accepted values are: optional, always, never
# export KITE_DATA_COLLECTION=optionalSpecify where Sphynx (the single-node server) is running.
export SPHYNX_HOST=localhost
export SPHYNX_PORT=50051Certificate directory for Sphynx, if an encrypted connection is desired.
# export SPHYNX_CERT_DIR=$HOME/kite/sphynx_certSpecify the PID file for Sphynx.
export SPHYNX_PID_FILE=$HOME/kite/sphynx.pidSpecify the directory where Sphynx stores graph data.
export ORDERED_SPHYNX_DATA_DIR=$HOME/kite/data/sphynx/orderedSpecify the directory where Sphynx stores graph data using vertex ids from the Spark world.
export UNORDERED_SPHYNX_DATA_DIR=$HOME/kite/data/sphynx/unorderedEnable CUDA if you have a compatible GPU and want to use it to process graphs.
# export KITE_ENABLE_CUDA=yesUnrestricted Python in LynxKite is a very powerful tool. Since Python execution has full access to the network and file-system, it must be explicitly enabled by the administrator.
# export KITE_ALLOW_PYTHON=yesUnrestricted R execution in LynxKite is a very powerful tool. Since R execution has full access to the network and file-system, it must be explicitly enabled by the administrator.
# export KITE_ALLOW_R=yesA simple chroot-based sandbox for executing users' Python code can improve security in a multi-user
environment. To be able to mount directories as read-only, this requires running LynxKite as root.
If it’s running in a Docker container, that container must be started with the --privileged flag.
# export SPHYNX_CHROOT_PYTHON=yesSphynx can keep entities in memory for high-performance computation. This setting configures how much memory to allocate for this purpose.
export SPHYNX_CACHED_ENTITIES_MAX_MEM_MB=2000Prefix definitions
The prefix definitions configuration file is used to specify what file paths users are allowed to access using what prefixes. It also serves as a means to provide user access control to certain prefixes if desired.
Special prefixes can be defined here that expand to directories or paths.
Suppose, for example, that the administrator specifies
DIR="file:/home/user/kite/" in this file. Then whenever the user references
DIR$subdir/data.txt (s)he will access the file:/home/users/kite/subdir/data.txt.
Moreover, there is no other way a user can refer to that file (unless there are
other prefixes defined here that make this possible).
Format:
Lines that begin with a hashmark (#) are comments and ignored.
Prefix symbols should only contain capital letters, underscore, and digits; the first character cannot be a digit. The dollar sign is NOT part of the prefix symbol.
The paths that they define should either be empty, or
end in an at sign (@) or end in a slash (/).
The defined paths should always start with a file system specification (e.g. s3n: or file:)
unless they are empty.
The quotation marks are not part of the path, but they should still be supplied.
Local prefixes (the ones starting with file:/) only work on
single-machine LynxKite installations. On distributed LynxKite installations, you will need
to use a distributed file system, like HDFS or S3.
Examples:
# LOCAL1="file:/home/user/old_kite_data/"
# LOCAL2="file:/home/user/old_kite_data2/"
# S3N_OLD_DIR="s3n://key:pwd@old_kite_data/"
# S3N_OLD_DIR2="s3n://key:pwd@"
# EMPTY=""A specification of EMPTY such as the one above gives the user
full access to anything; e.g., they can say
EMPTY$s3n://key:password@somedir/somefile or EMPTY$file://etc/passwd.
Prefix-based access control
Prefix symbol endings _READ_ACL and _WRITE_ACL have a special meaning: instead of specifying
a path, they specify user access privileges for a given prefix. Suppose you have defined the
following prefix:
# SENSITIVE_DATA="hdfs://sensitive_data/"By default, all users are allowed to access files such as SENSITIVE_DATA$secret.csv. This can
be changed by adding two extra lines to the prefix definition file, for example:
# SENSITIVE_DATA_READ_ACL="*@mycompany.com"
# SENSITIVE_DATA_WRITE_ACL="jack@mycompany.com,jill@mycompany.com"This gives read access to all users at mycompany.com and write access to users jack, and jill
(In general, an access control list is comma-delimited; (asterisk)
can be used as a wildcard; means all logged in users.
*@lynxanalytics.com, for example, means all users with user names matching that pattern.)
Note that this implies that you cannot have a prefix symbol that ends in _READ_ACL or _WRITE_ACL
because that would be interpreted as an access control specification.
Specifying neither read nor write access for a prefix implies * access; that is, any user can
read or write files accessed via that prefix. But if you specify either access type, you must
specify the other access type as well.
It is important to note that access control checks only the prefixes, but not the files itself. So, in such a setting
# ROOT="hdfs://root/"
# SENSITIVE_DATA="hdfs://root/sensitive_data/"
# SENSITIVE_DATA_READ_ACL="*@mycompany.com"
# SENSITIVE_DATA_WRITE_ACL="boss@mycompany.com"there is no use in providing read and write access to your sensitive data, because
although only boss@mycompany.com can write SENSITIVE_DATA$secret.csv, anyone
can read and write ROOT$sensitive_data/secret.csv, which is the same file.
So if you use prefix-based access control, make sure that the data protected is not
accessible via another prefix.
LynxKite backup
Making backup
If LynxKite was started with KITE_DATA_DIR pointing to an S3 bucket, then there is
an easy way to backup all the project information and computed data. For admin users
there is an backup menu entry in the Settings menu.
Backup configuration
This backup function is only usable, when LynxKite was started
with proper AWS credentials, and the environment variables KITE_DATA_DIR and
KITE_EPHEMERAL_DATA_DIR are set according to the admin manual.
A typical configuration may look like this:
KITE_DATA_DIR=s3://bucket_name/ KITE_EPHEMERAL_DATA_DIR=hdfs://hostname:port/hdfs/location/
The backup process copies the data from KITE_EPHEMERAL_DATA_DIR to KITE_DATA_DIR and
also copies LynxKite metadata to KITE_DATA_DIR/metadata_backup/VERSION/, where
VERSION is the current timestamp at the time of the backup.
The location of this metadata backup may look like this:
s3://bucket_name/metadata_backup/VERSION/
VERSION is a timestamp in the form YYYYMMddHHmmss.
Upgrade
Install new binaries
Just untar the tarball given by your Lynx Analytics contact, preferably to the same location as you have your previous version. The newly created files/directories will not collide with already installed binaries.
Install dependencies
Run conda env create --name lk --file conda-env.yml to install LynxKite’s dependencies.
Create backups
Make a backup copy of your .kiterc file and metadata directory. The location of the metadata
directory is configured in .kiterc. If your system is configured to perform automated backups
of .kiterc and the metadata directory you may skip this step.
Update configuration
You need to upgrade your .kiterc file to reflect changed and new configuration options.
All these changes are listed in the release notes, but you can in most cases perform this
update via a 3-way merge of the old configuration template, the new configuration template
and your existing config file. Assume your old LynxKite base directory is kite_OLD, your new
LynxKite base directory is kite_NEW and your current config file is .kiterc. Then you can
update the configuration via the following steps:
-
Backup your current config file:
cp .kiterc .kiterc.old -
Perform an automatic 3-way merge (you might need to install the
rcspackage to have the merge command available):merge .kiterc kite_OLD/conf/kiterc_template kite_NEW/conf/kiterc_template. -
Review the new version of
.kiterc. Look for merge conflicts (blocks surrounded by<<<<<<<and>>>>>>>). Make sure you understand all options and their values. Please contact the Lynx support team if you have any questions or doubt.
Stop currently running LynxKite version
Use the command kite-x.y.z/bin/lynxkite stop where x.y.z is the version of your original LynxKite.
Run the new version of LynxKite
Start the new version of LynxKite with kite-x.y.z/bin/lynxkite start, where x.y.z is the version
of your new LynxKite. Note that the migration can take several minutes when the upgraded
LynxKite is started for the first time.
Restore original LynxKite
If anything goes wrong and the new version does not work, you can always go back by
-
Stopping the new version of LynxKite
-
Restoring the original metadata directory and
.kitercfile -
Starting the old version of LynxKite