Cryptocurrency Analysis Tutorial
See this analysis in action! It's one of our working examples in the cloud demo.
Try LynxKite
Try LynxKite
Identifying cryptocurrency exchanges from transactions
Intro to the dataset
- Ethereum transactions are public, they are available in Google BigQuery following this link. Each row represents a transaction between two wallets (sender and receiver) and includes the receiving address previous balance.
- To have a manageable data size, we only use the first three months of 2019, summarised into monthly values and filtered the transactions with ETH value of 0 (those are usually smart contracts instructions). We also filter out wallets that have two or less connections and an average balance (taken from the receiving address previous balance) equal to 0. This way we reduce the data size from 6M to 145K, an acceptable data size for this demonstration.
- From etherscan.io we scrape the information of some known exchanges. We find 53 exchange addresses within our dataset. Having so few labels (0.03%) makes this an outlier detection problem more than a classification one.
Methodology
- We will do a cluster analysis to identify the different patterns that wallets follow. Then, we will identify the cluster that holds most of the labeled exchanges and conclude that the wallets within this cluster are more likely to be exchanges.
Intro to this tutorial
- Cryptocurrencies such as Ethereum have grown enormously in the last few years. Ethereum transactions are saved in a blockchain, which makes them completely public and traceable to the previous transaction.
- There are different players interacting in the Ethereum ecosystem, the most important are
the following:
- Users: People trading with Ethereum cryptocurrency.
- Exchanges: The ‘banks’ of the crypto world, they allow interaction with different types of cryptocurrencies and fiat money.
- Miners: Blockchain enablers, they spend computing power to introduce new blocks that register transactions.
- Smart Contracts: The differentiator between ethereum and the rest of cryptocurrencies, a set of transactional instructions embedded in the blockchain.
- Tokens: Digital assets for contracts within the Ethereum Virtual Machine, programmed to be used in the smart contracts.
- In this tutorial, we will try to identify which of the Ethereum addresses (wallets) are exchanges.
Build the graph
- First, import the filtered data with an Import CSV operation. Connect the wallets based on their transactions with a Use table as graph operation, setting the Source ID column to from_address and Destination ID column to to_address. Now we have our transactional graph created.
- Move the edge attributes to the vertices with two Aggregate edge attribute to vertices, one for incoming transactions taking the average of eth_value and to_address_prev_balance the max of eth_value_sum and the sum of num_txn; and the other one for outgoing transactions with the average eth_value, max of eth_value_sum and sum of num_txn. Every vertice has their respective incoming and outgoing attributes.
- Filter out disconnected vertices in the network, Find connected components and Aggregate from segmentation the maximum size of each node’s component. Then keep only the vertices which belong to the biggest connected component, filtering out those which connected_component_size_max attribute is less than 140000.
- Finally, rename the attributes to make them easier to handle:
- inedge_eth_value_sum_max to inedge_txn_max.
- inedge_num_txn_sum to inedge_txn_count.
- inedge_to_address_prev_balance_average to balance_avg.
- outedge_eth_value_sum_max to outedge_txn_max.
- outedge_num_txn_sum to outedge_txn_count.
- Now we have our clean graph, each vertex with their transactional attributes.
Calculate graph attributes
We compute many graph attributes that could help us identify exchanges.
- Modular cluster size:
- With a Find modular clustering operation, cluster the wallets according to their transactions. Aggregate from segmentation the first id and size of the modular clusters.
- Discard segmentations connected components and modular clusters, to keep the work environment size low.

- Transactions between modular clusters:
- Convert the modular_clusters_id_first vertex attribute to double.
- Derive edge attribute named txn_between_clusters with the following formula:
if(src$modular_clusters_id_first != dst$modular_clusters_id_first) 1.0 else 0.0 - Again, Derive edge attribute overwritting the previous one multiplying it with the
number of transaction that an edge has:
txn_between_clusters * num_txn. - Use an Aggregate edge attribute to vertices operation to transfer on all directions the edge attribute txn_between_clusters to the vertices.
- Discard all the edge attributes.
- Clustering coefficient: Approximate clustering coefficient.
- Page rank: Compute PageRank.
- Centrality: Compute centrality.
- Degree: Compute degree counting all neighbors.
- Proportion of incoming transactions: Derive vertex attribute with value
inedge_txn_count/(inedge_txn_count+outedge_txn_count). - Proportion of transactions between clusters: Derive vertex attribute with value
total_txn_between_clusters_sum/(inedge_txn_count+outedge_txn_count). - Total number of transactions: Derive vertex attribute with value
inedge_txn_count+outedge_txn_count - Average value of transactions: Derive vertex attribute
with value
(inedge_eth_value_average*inedge_txn_count + outedge_eth_value_average*outedge_txn_count)/(inedge_txn_count+outedge_txn_count) - For the calculated vertex attributes with constant 0 values.
Modeling
- Before we perform a clustering algorithm, we need to scale the data. For each vertex attribute
except the attributes that already are in a 0-1 scale (proportion of incoming transactions,
proportion of transactions between clusters and clustering coefficient), do the following
calculation:
- Log transformation: Derive vertex attribute with the formula
Math.log(attribute+1). - Find Max and Min: Aggregate vertex attribute globally and get the max and min of the log transformed attribute.
- Scale: Derive vertex attribute with the formula
(log_transformed_attribute - log_transformed_attribute_min)/(log_transformed_attribute_max - log_transformed_attribute_min).
- Log transformation: Derive vertex attribute with the formula
- Save the scaling process in a single custom box to make it easier to reproduce later.
- Now we can cluster the vertices into groups with a Train a k-means clustering model
operation. We tried several times to determine which are the attributes that differentiate
better the exchange wallets from the rest, comparing how many labeled exchanges were grouped
in a single cluster and determined that the optimal setting is 4 clusters with a combination
of the following features:
- Clustering coefficient.
- Degree.
- Inedge transaction count.
- Inedge transaction max.
- Inedge value average.
- Outedge transaction count.
- Outedge transaction max.
- Number of transactions between clusters.
- Classify each vertex with a Classify with model operation and name them cluster, convert the new cluster attribute to string and with a Segment by String attribute group them into the new clusters.
- Import the scraped exchange wallets dataset with an Import csv operation.
- Join the exchange labels with an Use table as vertex attributes operation, connecting the vertex attribute stringId to the ADDRESS column.
- From the CATEGORY imported attribute compute exchange and for miner identifiers with two
Derive vertex attribute operations with the following values
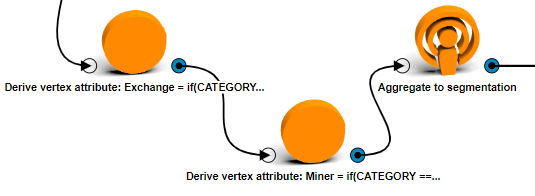
if(CATEGORY == "Exchange") 1.0 else 0.0andif(CATEGORY == "Mining")1.0 else 0.0. Name them Exchange and Miner, respectively. - Aggregate the sum of these new attributes and the average of every transactional attribute to the cluster groups with an Aggregate to segmentation operation.
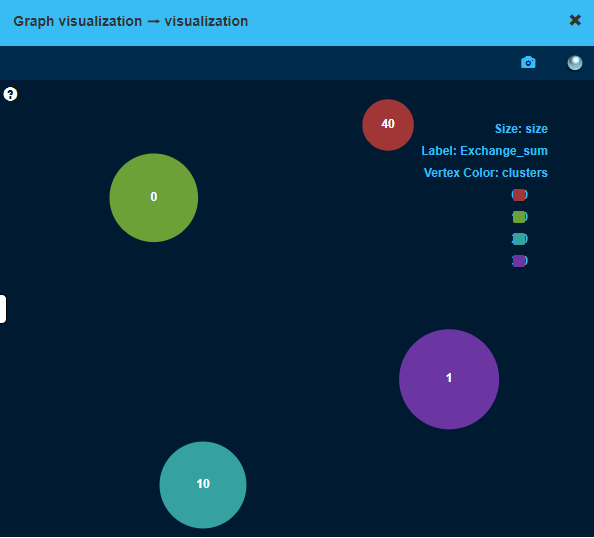
- With the help of a Graph visualization operation on the segmentation, visualize the distribution of exchanges in the clusters by setting the Exchange_sum attribute as label, the cluster as color and size as size. You can play with this attributes to see how the cluster differ from each other.
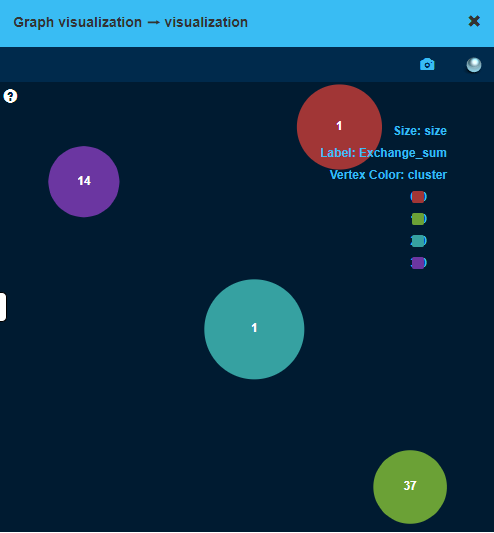
- We managed to group 96% of the identified exchanges in two clusters. It seems that there are two main behavioral patterns between exchanges. On the other hand, most of the miners (65%) also belong to the same clusters, which means that our model fails at discerning wallets from exchanges and we need to build another clustering model to separate them.
- Use a Filter by attributes operation to keep only the vertices that belong to the chosen clusters.
- Discard the previous segmentation, the cluster model (which is a scalar) and the scaled vertex attributes (we need to re-scale them) along with the cluster attribute.
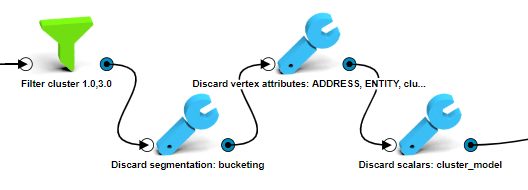
- Copy and paste the scaling process which we previously saved as a custom box to re-scale the required attributes.
- Train another cluster model. Again, we’ve iteratively combined different attributes to see
which differentiate exchanges from miners, determining the best combintation, again into 4
clusters, of the following scaled features:
- Balance.
- Inedge transactions count.
- Inedge transactions max.
- Outedge transactions max.
- Page Rank.
- Proportion of transactions between clusters.
- Again, classify the vertices with the developed model, transform the classification attribute into string and segment the vertices according to this new attribute.
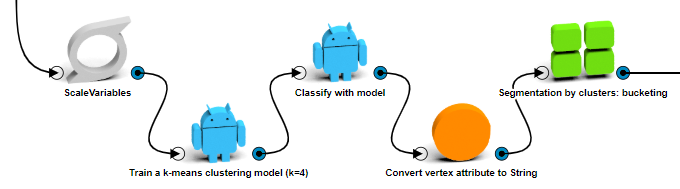
- Copy and paste the Aggregate to segmentation and the Graph visualization operation so that we can check again the results of this last clustering model. Out of the 53 initial labeled exchange wallets, 50 fall into 2 of the current clusters. Even though some of the miners still fall within this clusters (10 out of 49), the proportion of exchange wallets is a lot higher.
- Finally, we can keep the two clusters that have high proportion of exchange wallets and download the vertices with an SQL1 and an Export to CSV operations.
Results
- We tackled a complex outlier detection problem using an unsupervised learning technique. Out of 145K initial wallets, we managed to find 20K (~13%) with a higher probability of being exchanges. From these wallets we determined two types of exchanges, one of smaller and less known exchanges like Huobi or Cobinhood and another one of bigger exchanges like Binance or Bittrex.