Combined Text and Graph Embeddings
The recently released LynxKite 5.4 has added support for text embeddings. This makes it easy to combine the power of graph-based machine learning and large language models like never before.
Introduction to embeddings
Machine learning models, from a lowly linear regression to the latest transformer, all rely on vector representations of their inputs. The input data must somehow become a fixed length sequence of numbers.
-
Working with structured data is the easiest. We can construct a feature vector by simply listing the properties of each data point. Categorical data can be represented as a series of ones and zeros.
-
Text data is more challenging. We could simply associate each letter with a number. This is basically how the input of large language models (LLMs) is formatted. But this format is inefficient for prediction tasks. We would rather have vectors that capture the meaning of the text. The best way to create such vectors is letting a language model learn how to create them. These vectors, called embeddings of the text, can no longer be interpreted by humans. But they capture the essence of the text. What exactly gets captured depends on the downstream task that the model is trained for. Large language models (LLMs) are capable of a wide variety of tasks, so their embeddings are very versatile.
-
Graph data can also be turned into vector embeddings using graph neural networks (GNNs) or other graph embedding methods. These embeddings capture the structure of the graph. We can create embeddings for individual nodes or edges, or for the entire graph.
Other modalities, like images and sound have their own embedding methods. The resulting vectors are all just lists of numbers. That means we can combine embeddings from different origins by simply concatenating the vectors.
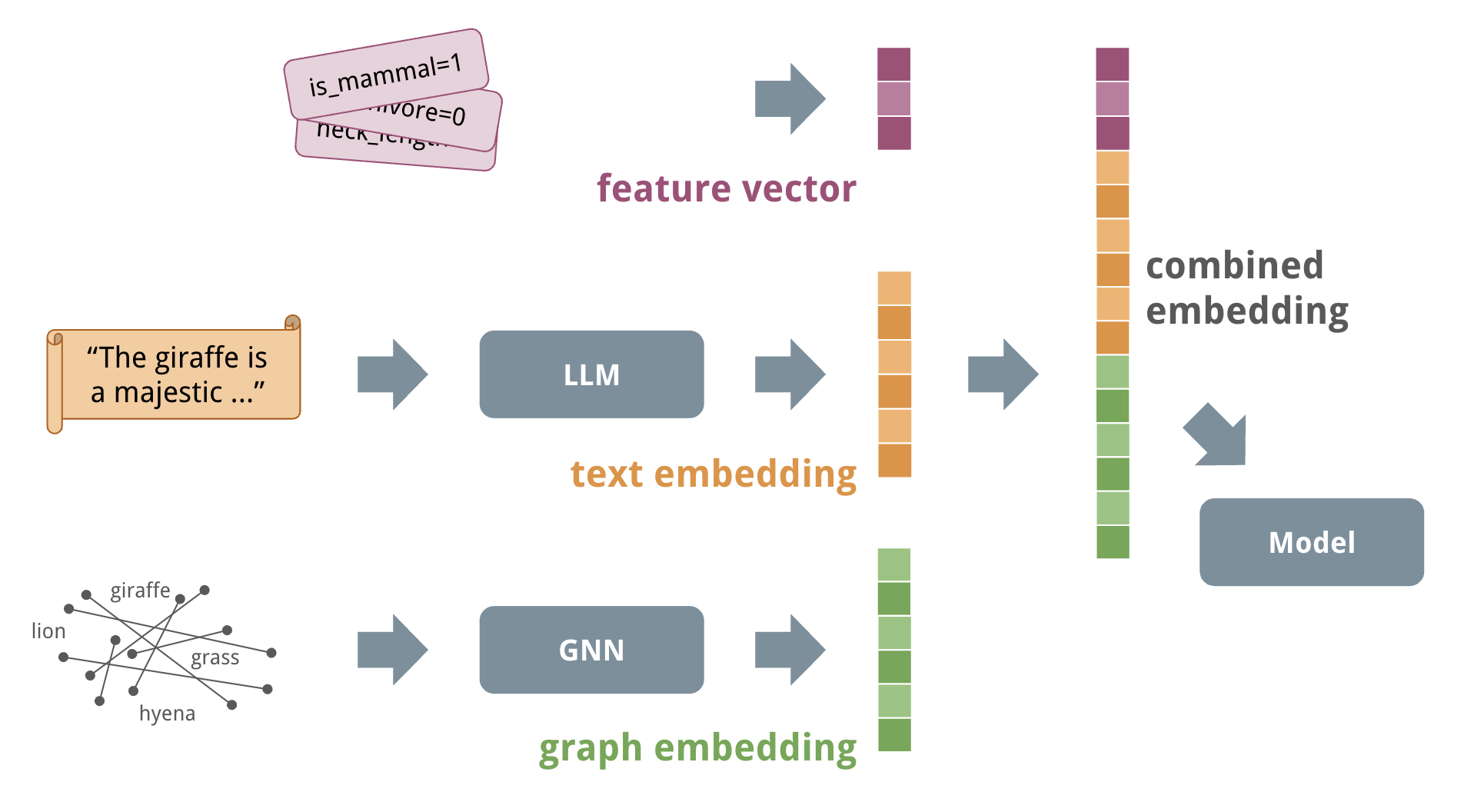
Combined embeddings are important for multi-modal datasets. Graph datasets often have text data associated with the nodes or edges. Until now, you had to make a choice to train a model on the graph structure in LynxKite or on the text data in another tool. One or the other would be more accurate each time. (We were always rooting for the graph model.) But now you can train a single model that uses both the graph and the text data, and it will be more accurate than either alone.
Here’s how it works!
Creating text embeddings in LynxKite
LynxKite has a number of operations for constructing a feature vector (such as Embed vertices) and operations for training models on these vectors. The new operation added in LynxKite 5.4, called Embed String attribute, turns text into a feature vector. It can compute embeddings for string attributes on nodes or edges using OpenAI models or open-source models.
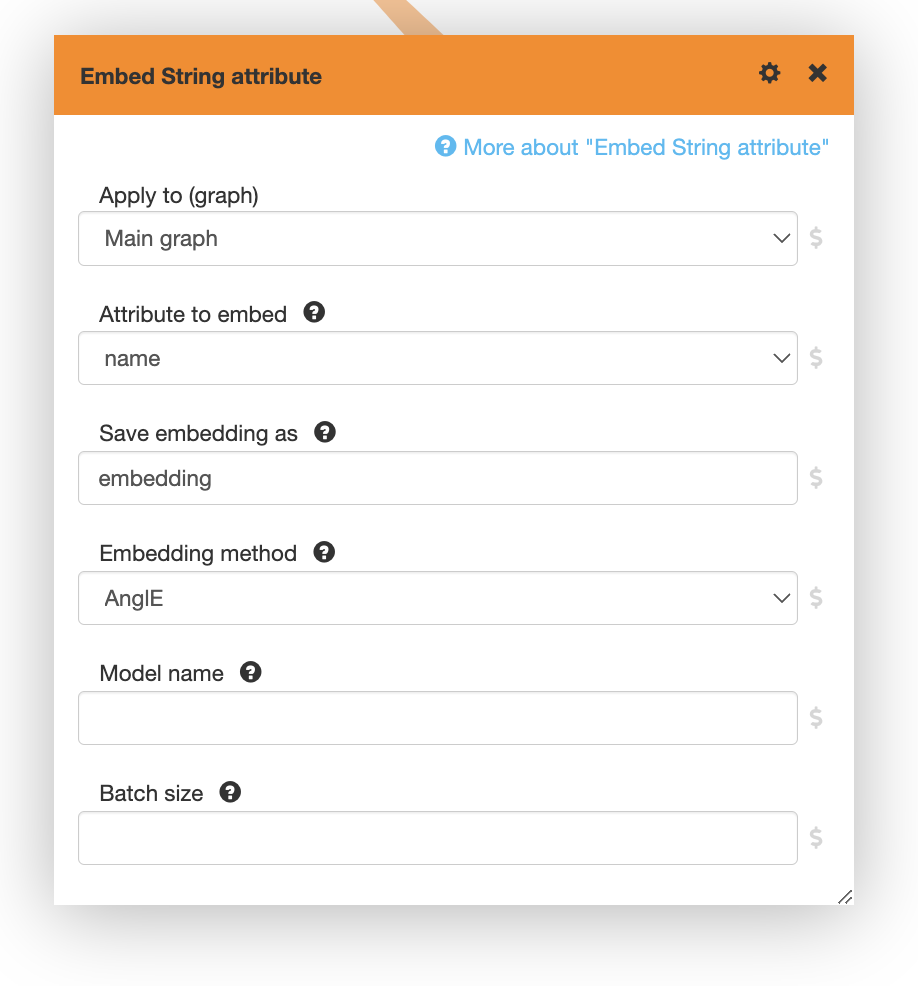
To use an OpenAI model, just select “OpenAI” as the embedding method. The default model is text-embedding-3-small.
See the OpenAI documentation for all available models.
You have to set the OPENAI_API_KEY environment variable to your OpenAI API key.
You can find thousands of open-source models on the Hugging Face model hub. Different models use different methods for generating embeddings. LynxKite supports the following options:
-
SentenceTransformers: Use this if the model is loaded with
SentenceTransformer(model_name). The default model isnomic-ai/nomic-embed-text-v1. -
AnglE: Use this if the model is loaded with
AnglE.from_pretrained(model_name). The default model isWhereIsAI/UAE-Large-V1. -
Causal transformers are generally not designed for embeddings. They still perform well with the echo embeddings algorithm that LynxKite implements. Use this if the model is loaded with
AutoModelForCausalLM.from_pretrained(model_name). The default model ismicrosoft/DialoGPT-small.
Our default models are some of the best performers in their size category. You can use larger models for better performance. The selected model will be automatically downloaded the first time you use it, adding some delay to the first run.
Examples
Text embeddings let you apply simple machine learning models to text data. The text data can be anything from a name to a comment or a full article. The following examples illustrate the variety of domains where this approach can be useful.
Demographic estimation
For marketing or market research purposes, we may want to estimate the demographic attributes of our customers. Graphs are a powerful tool for this. But if we have any text data, such as the person’s name, that can be immensely helpful too.
In this example I’m creating synthetic data with Faker. I mixed English, Chinese, and Greek names. With this mix the task is not as simple as learning that “John” is a man and “Mary” is a woman. A language model creates embeddings from the name attribute and a logistic regression model learns to predict the gender based on the embedding. The logistic regression model is trained in less than a second and it gives great results.
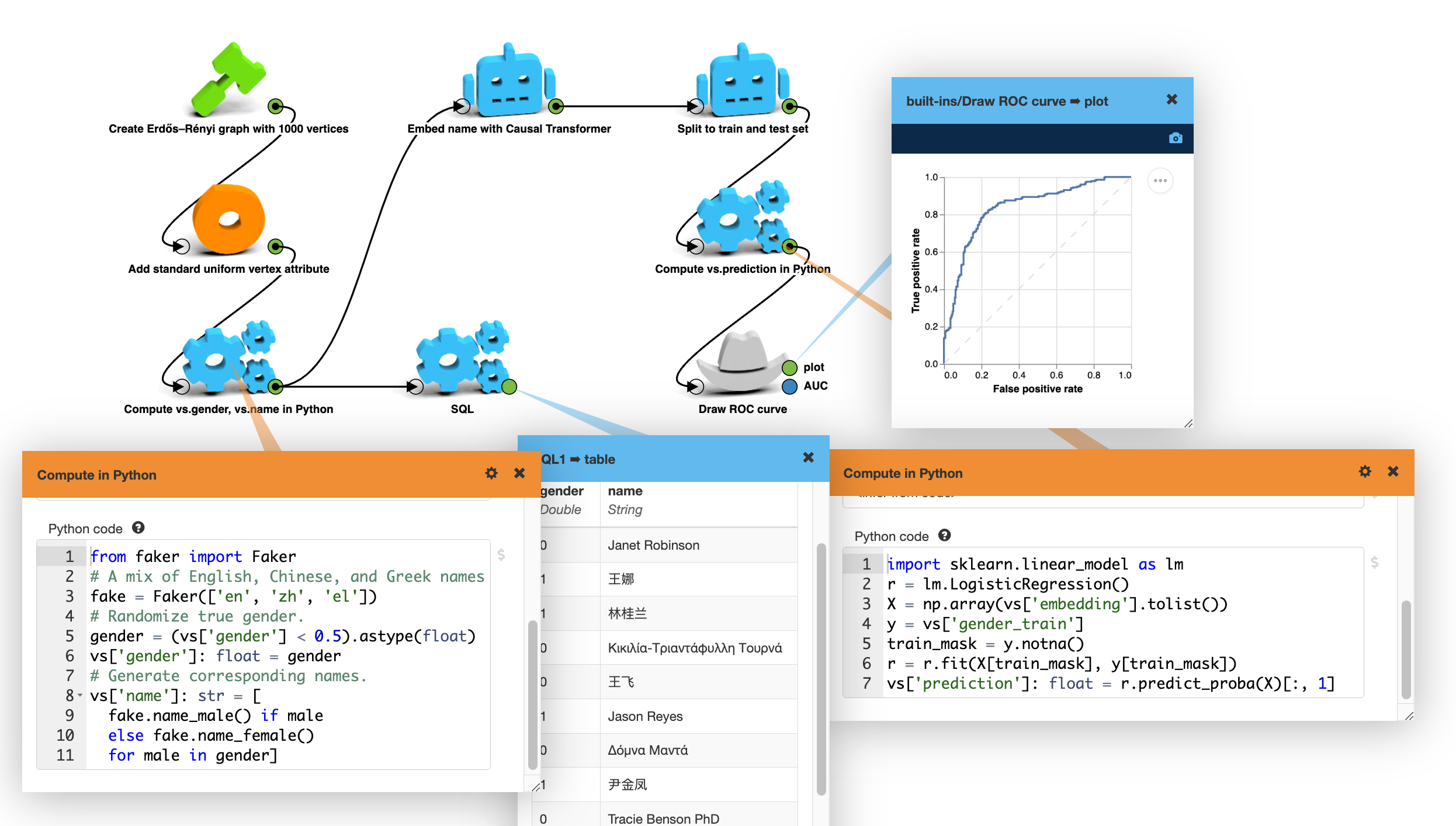
Predicting gender based on the name of a person. (Synthetic data.)
The LLM was not trained to know anything about names and genders. It’s a tiny 174 million parameter
model trained for conversation. (microsoft/DialoGPT-small)
Still it understands text, and the logistic regression can pull the right answer out of it.
Sentiment analysis
I’ve applied the same model (LLM and logistic regression) to a different dataset. It’s a collection of Twitter messages related to airlines. (CrowdFlower’s Airline Twitter Sentiment dataset.)
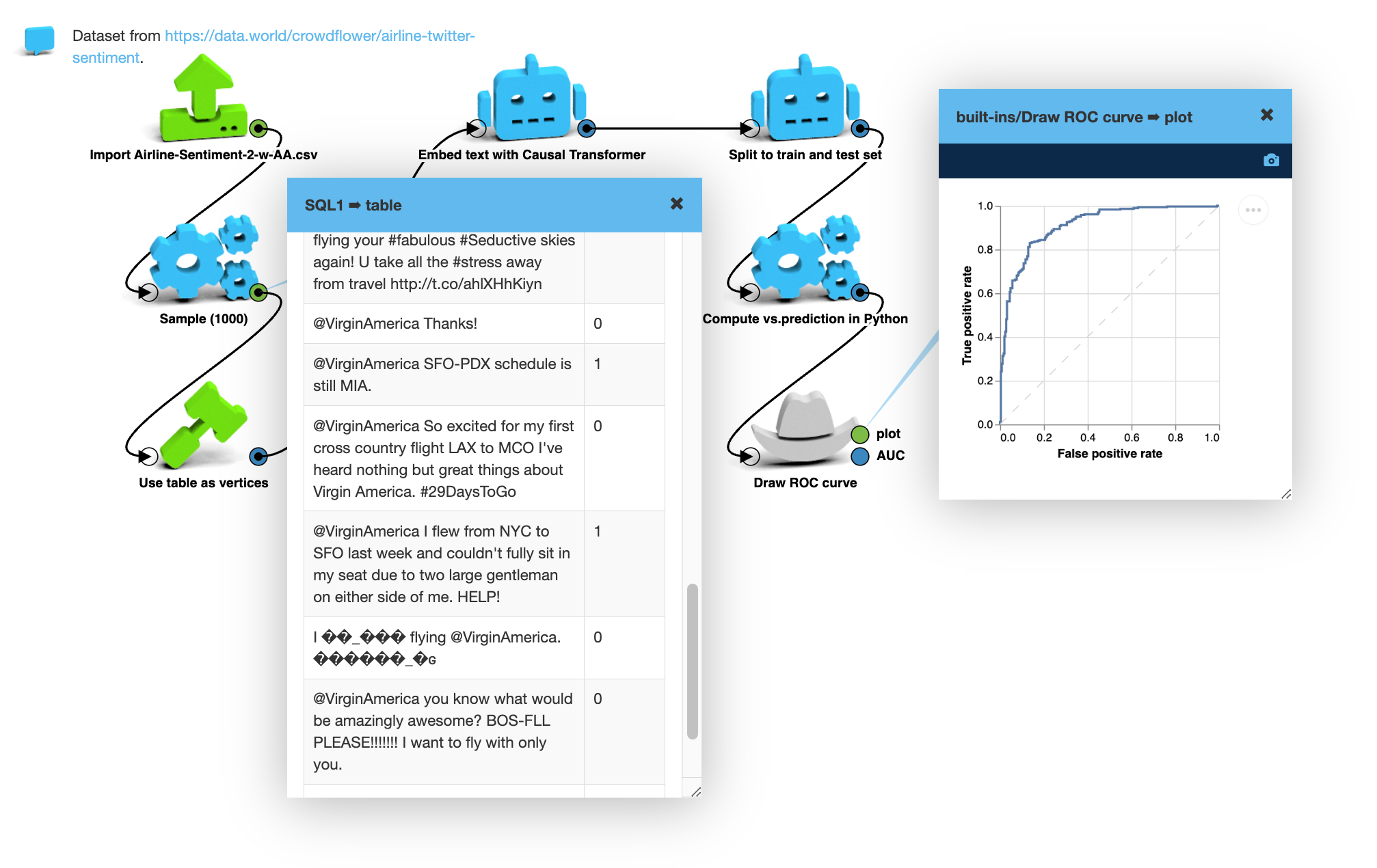
Predicting comment sentiment based on the text.
Medical transcripts
The same approach works for longer, more specialized texts as well. Here’s an example using a dataset of medical transcripts. The structured part of the dataset marks entries that involve surgeries. I trained the logistic regression model to predict this from the text.
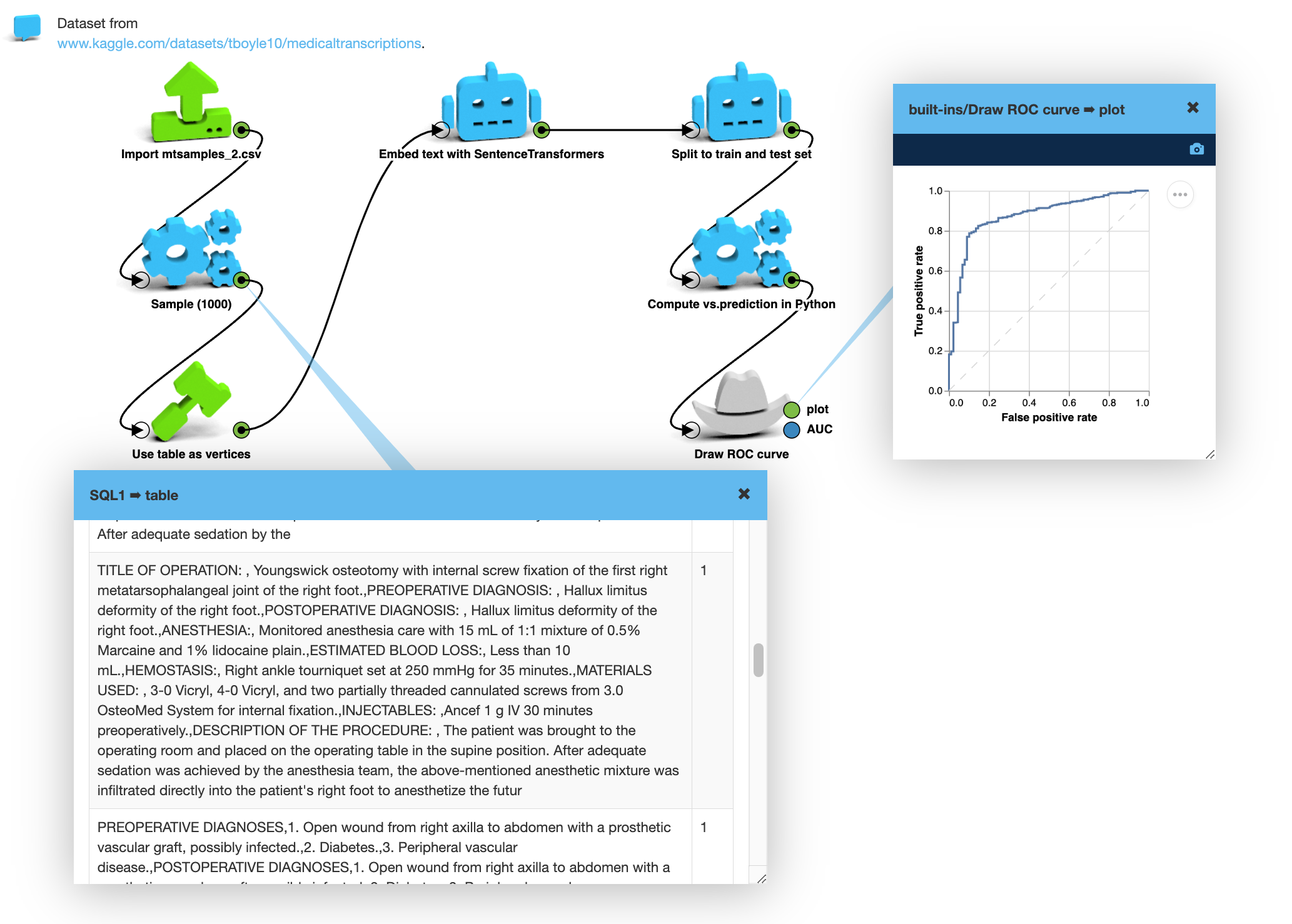
Predicting whether each medical transcript is marked as “surgery” or not.
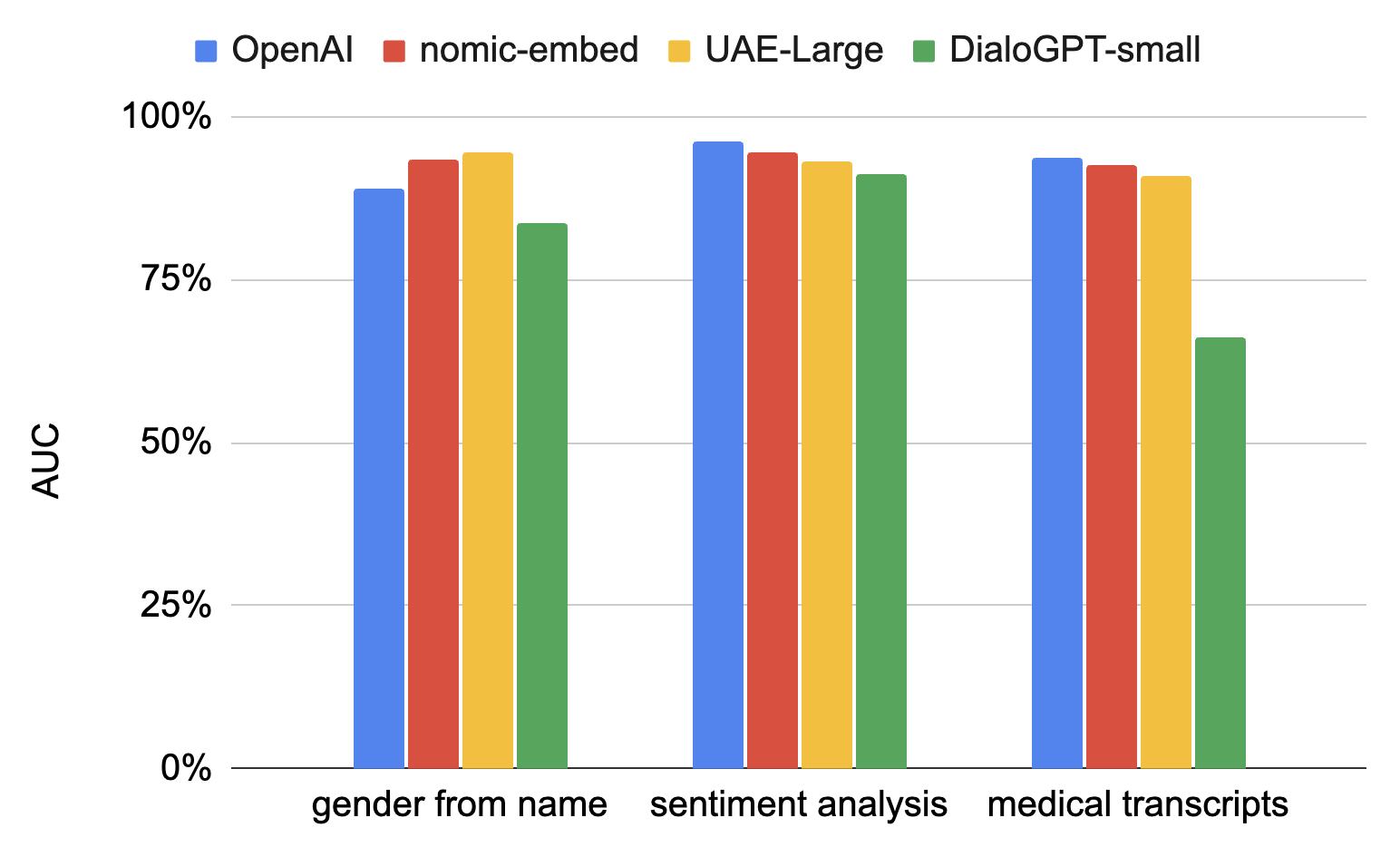
Comparing LLMs
None of the embedding models were trained for the tasks that I used them for. It is amazing that they work so well. But different models may be best for different use cases. LynxKite makes it super easy to try different models on the same task. I compared the performance of our four default models on the three example tasks.
Text + Graph
I’ve focused on the text embeddings in these examples. But the most exciting option is to combine text embeddings with topological embeddings using the Bundle vertex attributes into a Vector box. This concatenates the two embeddings, making them both available to the machine learning model.
Here’s an extended version of the first example, where I have introduced an asymmetry in the edge generation. I discard some edges based on the random number used for picking the source and target person’s gender. (Overall two thirds of the edges are discarded.) I have also made the problem more challenging by deleting the names of half the nodes.
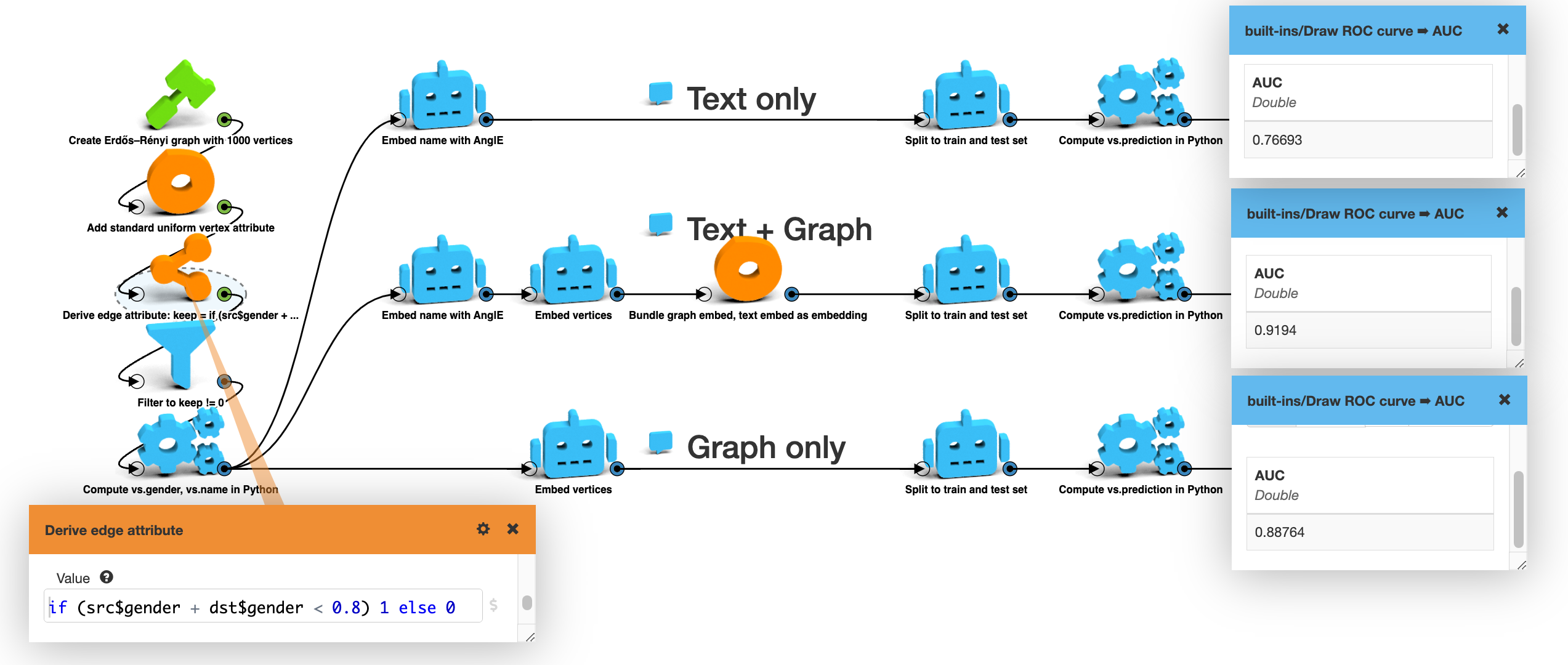
Predicting gender based on the name of a person. (Synthetic data.)
The AUC for the model using only the text embedding has dropped to 0.77. The model using the graph embedding alone scores 0.89. The model that uses the two embeddings together works best. It scores 0.92.

The AUC scores we get from different embedding options. (The higher the better.)
LynxKite makes it easy to experiment with different combinations of embeddings and models. LynxKite 5.4 also comes with a more permissive license than previous versions. (AGPL → Apache 2.0) We changed the license to simplify deployment in commercial projects, where we see the greatest demand for working with text data and graphs at the same time.
Let us know what you build with LynxKite and which combination of embeddings works best for you!
All the examples presented in this post are available on try.lynxkite.com. You can also try the article analysis wizard to see embeddings in action on a text of your choice.