Your Code in LynxKite
LynxKite provides hundreds of built-in operations from computing the degree of nodes to finding a coloring of the graph and making predictions with a neural network. But what to do if there is no built-in box for what you want? LynxKite has many different options for you to use your custom formulas and code. In this post I review all of them and explain why I would choose one over the other in different situtations.
Option 0: Write your own code without using LynxKite
I wanted to include this as a baseline. Of course this is the most flexible option. You can use whatever programming language you like and there is no limit on what you can achieve.
The downside is that you are now responsible for all the conveniences you enjoyed in LynxKite. Importing a file is no longer a simple drag & drop. Visualizing the graph is not just one click away. You can’t just run a SQL query anytime you need.
Option 1: SQL in LynxKite
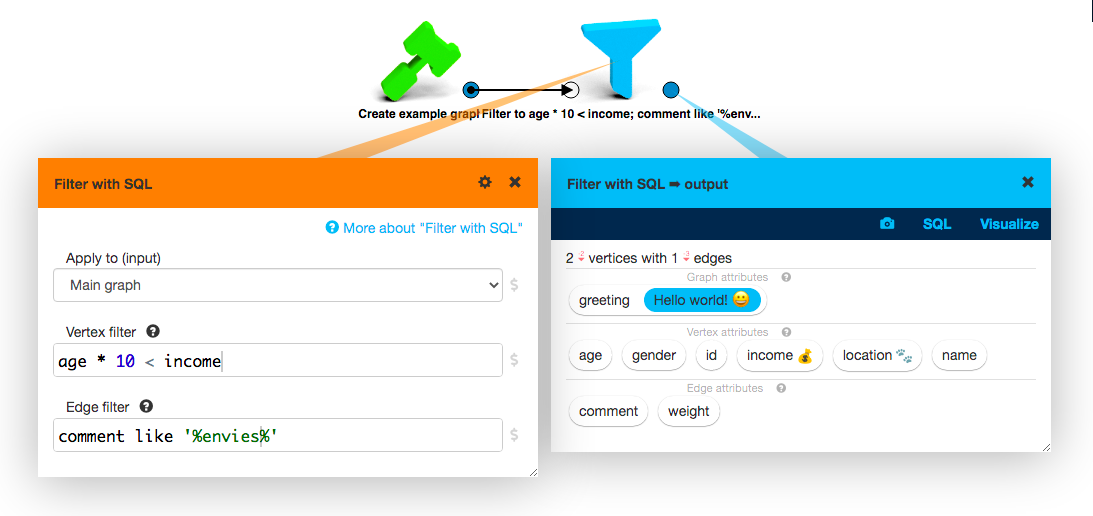
Many graph-oriented systems offer special graph-oriented query languages, such as Neo4j’s Cypher or TigerGraph’s GSQL. LynxKite uses plain old SQL instead. While it doesn’t have the expressive power for complex pattern matching or implementing traversal algorithms, it is simple and familiar. Want to see the average of a value defined on the edges grouped by an attribute of the destination nodes?
SELECT dst_name, AVG(edge_weight) FROM edges GROUP BY dst_name
LynxKite has rich support for relational tables too, not just graphs. You can run SQL on them of course and join them with graphs if you like.
SELECT * FROM `graph.vertices` INNER JOIN table USING (name)
The queries are executed on Apache Spark, so you can use the full syntax of Spark SQL.
The SQL queries always return tables, even when executed on a graph. If you want to use SQL to pick out a subgraph, this is an inconvenience. This is exactly the reason why we are adding the Filter with SQL box in the next release of LynxKite.
Option 2: Scala in LynxKite
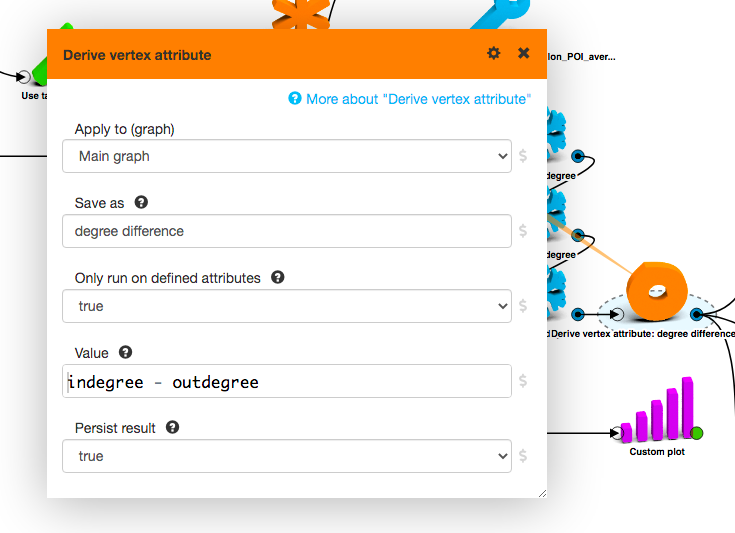
LynxKite is written in Scala. This should explain why we had the idea to add Scala expression support in the Derive attribute boxes. But why did we actually do it?
Scala is a functional programming language. A relevant upside of
this is that expressions in Scala can grow to humongous sizes. While a + b is a valid expression
in Scala, SQL, and Python, what happens if you want to compute the same function on a and b
before adding them? You cannot have function definitions inside an expression in Python. (And you
don’t have function definitions at all in SQL.) But in Scala these two lines are a valid expression:
def f(x: Double) = Math.sin(x) / (1 - x)
f(a) + f(b)
We could have worked around this in Python the same way that Jupyter cells handle it: take the value of the last expression as the output of the cell. But Scala is also a compiled language. When the expression is compiled, we learn the type of its output, without having to execute it. And we can execute the compiled code for each node or edge of the graph much faster than if we had to repeatedly execute Python code.
Option 3: Python in LynxKite
Python is the native language of data scientists. Once we had added
Sphynx, our high-performance
single-node execution backend, we had a way of adding Python support. Python can be fast if
we use vector operations. Thanks to Numpy, Pandas,
TensorFlow, and PyTorch,
using vector operations is now the norm for Python users. Want to add two arrays of numbers
element-wise? Instead of a for-loop, you just write a + b.
The Compute in Python box in LynxKite loads the parts of the graph that you want to use into Pandas DataFrames (one for vertices and one for edges). You can then add new columns to these DataFrames to create new attributes on the graph.
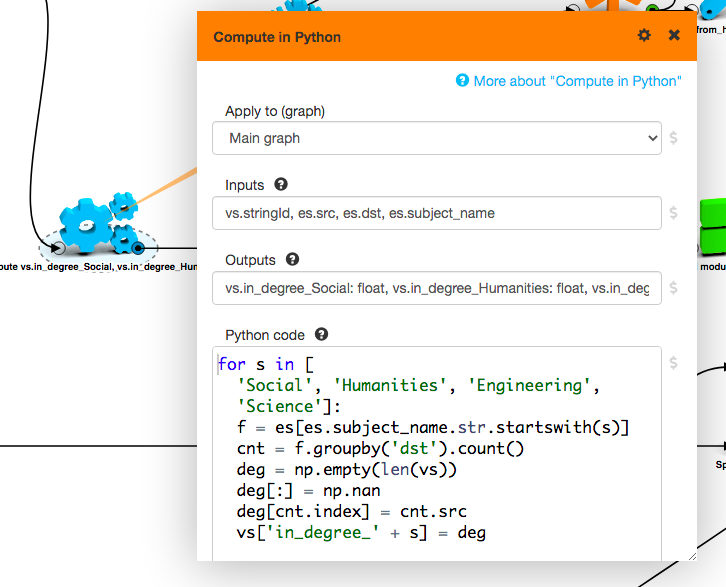
A huge advantage here compared to the Scala expressions is that you have access to the whole graph in memory at once. This means you can execute complex graph algorithms, such as those involving a traversal of the graph.
Option 4: LynxKite in Python
It can also be the case that LynxKite can do what you want, but you want to integrate it in a Python program. A common reason for this is that you’ve finished the creative phase of data science and now you just want to run the same pipeline on the new data as it arrives every day.
When this comes up, just select the part of the workspace you want to move to Python and click the code button in the toolbar.

This gives you the Python code equivalent for those boxes. The generated code can be quirky, but after some cleanup the API is actually straightforward.
import lynx.kite
lk = lynx.kite.LynxKite()
eg = lk.createExampleGraph()
print(eg.computeDegree().sql('select avg(degree) from vertices').df())
Read our Introduction to the LynxKite Python API for more technical details. But the short story is that anything you can do through the UI you can also do through the Python API.
This API uses a connection to a running LynxKite instance. This means there are no performance concerns either. Even if you trigger them from Python, the operations will still run on Apache Spark or Sphynx (the Go backend). In fact, the Python API builds a full-blown LynxKite workspace as it executes your code. This is helpful if something goes wrong and you need to troubleshoot a data issue. You can open up the UI and spot check intermediate results with visualizations and SQL queries until you track down the problem.
Option 5: Python in LynxKite in Python
Now we are getting to the more arcane use cases. But it may happen that you want to run an external system as a step in a LynxKite workflow that is triggered from Python. When executing such a mixed pipeline, you need to execute all the LynxKite operations that create the inputs of the non-LynxKite operation, then the non-LynxKite operation, then the rest of the LynxKite pipeline.
This is made super easy with the
@external decorator
of the Python API:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('test').getOrCreate()
@lynx.kite.external
def stats(table):
df = table.spark(spark) # The input as a PySpark DataFrame.
return df.groupBy('gender').count() # Return the output as a PySpark DataFrame.
eg = lk.createExampleGraph().sql('select * from vertices')
t = stats(eg)
t.trigger()
print(t.sql('select * from input').df())
The external code will run in the same Python process as where we called t.trigger().
There is no dark magic, just synchronization and automatic conversion in both directions.
(PySpark is just one of the input/output formats supported.)
Option 6: LynxKite in Airflow
As you get into it, these Python LynxKite pipelines can get out of hand. We have installations that process hundreds of inputs files through pipelines that also interact with each other. When something fails, you don’t want to just see a message telling you the whole process has failed. You want to know which part and which step. Was it the cleaning of the data? Was it the training of the model? Was it the scoring or the pre-aggregation for a dashboard? And you also want to be able to retry some part after an upstream issue is fixed. You want to force a successful part to rerun sometimes.
All this functionality is already covered by job scheduler systems. We did not open-source this part, because it is not generally interesting for individual users. But in LynxKite Enterprise we have an abstract integration with job scheduler systems. While this makes it quite easy to integrate LynxKite pipelines with any scheduler system, most of our experience is with Airflow. For Airflow we provide perfect integration out of the box.
Option 7: Contribute on GitHub
We also welcome contributions on GitHub. You can implement
whole new boxes in Scala or Go. Or if you have built a
custom box that is generic enough to
be useful for other, just copy-paste it into a pull request for
built-ins and it can go live in the
next release. Or if you just see a typo or a bug, a report or a pull request is very welcome.
Nostalgia for JavaScript and Groovy
If you look back in our code to LynxKite 1.14.0 from 2017, you can see that back then we had JavaScript where we now use Scala, and Groovy where we now use Python. We used JavaScript because of its easy sandboxing and Groovy because of its easy integration with a JVM application. But in the long run they became a technical debt more than anything else.
Even if we don’t count these two, it’s clear that we have an extensive array of language integrations. Is it just Zawinski’s law? I think it’s a natural accumulation of features over a long time of active production use. Each of these integrations has been key to a successful project at some time, and they are still useful today. And if you’re just starting out, you don’t have to learn all of these. Just pick SQL or Python (whichever you’re familiar with) and you can accomplish anything you want.